Building the Automation
I had my data. Now I needed somewhere to put it.
Obsidian stores everything as plain markdown files with no database and no cloud lock-in. Just text files I own and can read with any editor.
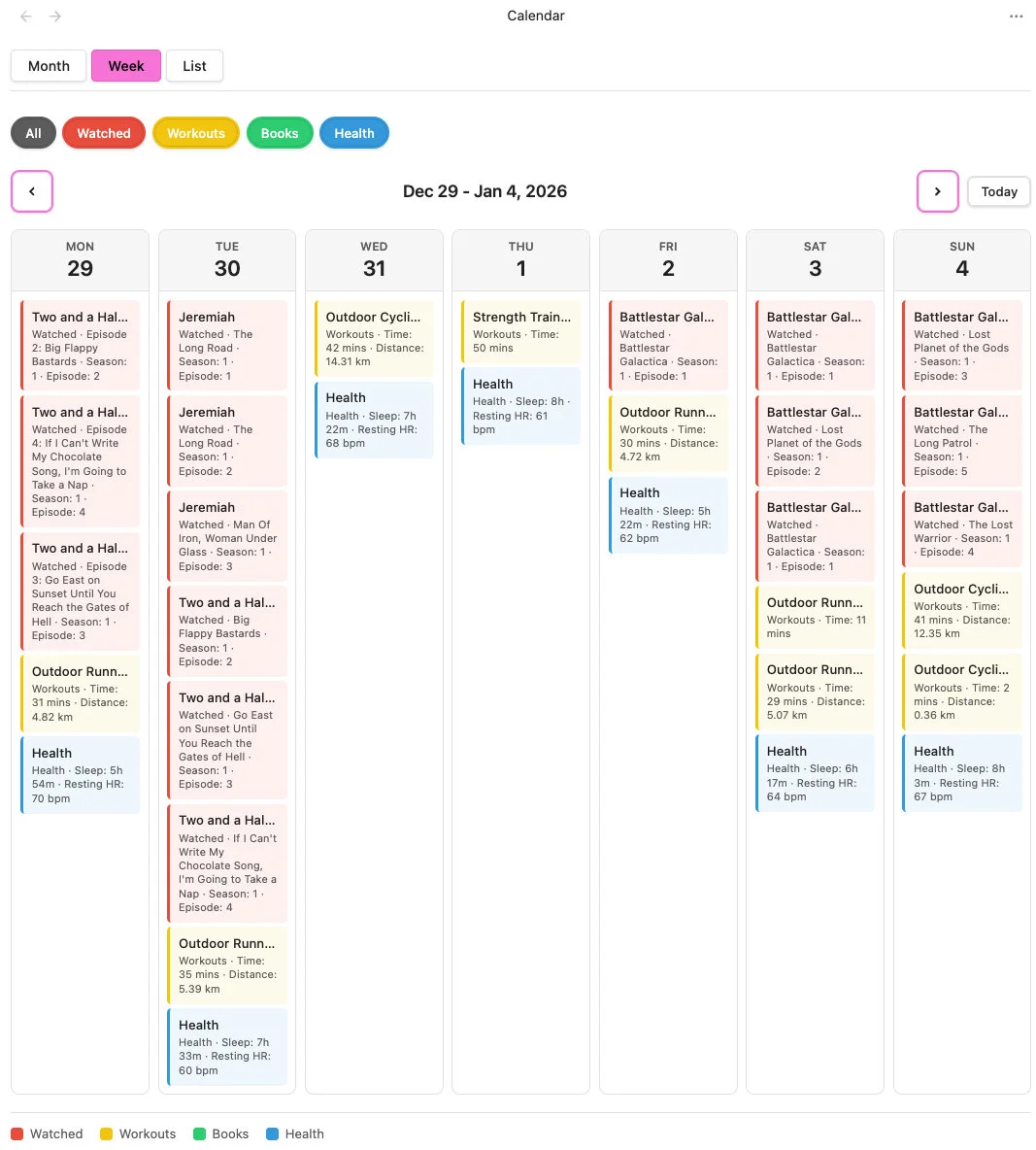
The image is of my calendar's week view as we crossed over to 2026, honestly I don't binge watch shows, it must be someone else with my login.
Steph Ango, CEO of Obsidian, links everything in his vault even if the note does not exist yet. That simple idea triggered something in me: I am not building a journaling system, I am building connections. Authors become notes, genres become notes, streaming services become notes, and when I look at an author I see all their books. A knowledge graph built from text files.
Everything must work on my iPhone because I am not always at my desk. This ruled out Node.js dependencies and desktop-only plugins so every script uses Obsidian's cross-platform APIs.
I wanted sync across devices without paying for Obsidian Sync. iCloud was the obvious choice but it did not work with my existing repository. My solution was to split the vault into two GitLab repositories with content in one synced via iCloud and build config in another. Commits to content trigger the build pipeline. One discovery: the iPhone app creates its own iCloud directory and cannot read a vault created by the Mac app unless the vault was originally created on iCloud.
After testing many community plugins I reduced them to three: Git for version control, QuickAdd for custom scripts, and Local REST API so Chrome extensions can talk to Obsidian. Plus one I built myself: Calendar View with month, week, and list views, multiple sources with colour coding. I built it because nothing let me see shows, books, health and workouts together on a calendar.
The combination of Cursor and Claude Opus 4.5 changed how fast I could build. Fifteen minutes from identifying an issue to seeing results. That speed keeps momentum strong, and momentum is what gets things finished.
QuickAdd runs JavaScript inside Obsidian so I wrote scripts for each domain. Books use Google Books API with Apple fallback and AI summaries via local Ollama, shows use TMDB with fuzzy matching for services that number episodes differently, and health imports daily metrics. All scripts track progress so batch imports can resume.
If you build your own tools instead of accepting limitations, I would love to connect.
Read more: Personal Data Hub